


Automating the Drug Discovery Lab of the Future: Part 4 Physical Automation
This is the fourth in the continuing series:



PART 4
Time for robotics:
Finally, when data acquisition and analysis are automated and you’re able to track the quality and quantity of data over time, then it’s time to bring in the robots. These things are expensive to purchase and it’s important to monitor the investment and make sure it is deployed in an area that will have the most value. As we walked through our processes, we identified several key points where automation could be applied and began developing solutions. In retrospect, these fell into three categories:
Crucial: In our workflow, protein purification and magnetic bead separation workflows require hours of time spent mixing 8-96 reactions in parallel as well as several sequential wash steps where the timing between steps is important. These steps truly cannot be performed without automation.
Tedious: Sorting and organizing 96 different tubes of PCR primers and ensuring that each is paired up correctly with one of 48 different samples is critical to associating each data file with the correct experiment. The same can be true for tracking hundreds of purified proteins into individual storage tubes.
(not) Helpful: Many tasks could be automated with a pipetting robot—like bulk reagent dispensing or quantification plate prep—but that doesn’t always mean they should be.
Crucial Tasks:

The KingFisher Duo Prime is a simple workhorse for moderate-throughput magnetic bead separations
Initially we purchased purified proteins and then needed to mix them with magnetic beads, then our DNA encoded library, and then wash those beads so that only the proteins and tightly bound molecules remained. These steps need to be run consistently from sample to sample so that results are comparable. We chose the KingFisher Duo Prime for this purpose. It can process 12 samples in a row across two plates of 16 rows, and it was simple and inexpensive. This was also the first instrument that we duplicated. There was no effective manual workaround if it went down. All of our results were dependent on it.

The Hamilton Star platform is a ubiquitous, flexible and robust automated pipetting system
Most of our protein production process is done manually in large volume flasks that spend the bulk of their time shaking in an incubator. The manual interactions with these flasks are generally quick and sterility is crucial. Automating here would be expensive and introduce significant contamination risks so we’ve not attempted to automate this process. However, at the end of the workflow when 96 culture systems are lysed the purification process takes hours for each sample. Automation allows us to parallelize this to 96 at a time. From past experience we knew that the chemistry enabled by the tip-based protein affinity purifications from Integrated Micro-Chromatography Systems would provide the quality and purity we needed. Plus they provided method packages for the Hamilton Star with application support making it quite quick and easy for us to get the system up and running. These machines are expensive, and can be purchased used. It’s been my experience that refurbished systems can work as well or better than new systems provided you’re working with an experienced reseller like Copia Scientific.
Tedious Tasks:

I ended up buying this tube scanner on Ebay. Getting the software running without support was a bit of a pain, but it’s been a great addition to the lab.
As we scaled up to 48 selections and 96 protein purifications per day, the number of PCR reactions per pool also began to grow. When there are only 12 samples per day it’s reasonable to manually find the right primers for each sample and pipette them one at a time. When it’s 96 samples and 192 primers this becomes difficult. We implemented 2D barcoded tubes from Fluid-X that were relatively easy to handle manually due to large screw-cap tubes and human readable, 1D and 2D barcodes. The Hamilton star has a flatbed scanner that can read the 2D barcodes 96 at a time. We can pass in a list of barcodes to pipette and it can translate that into a list of locations to pipette based on where it reads those barcodes.
Recording barcodes, decapping and recapping tubes, and pipetting in and out of them are incredibly tedious tasks. They can be done manually, but the level of concentration required to do them accurately without error is exhausting. This is a perfect problem for automation to solve.
(not) Helpful Tasks:
We might have saved a lot of time at Leash avoiding the implementation of “helpful” automation tasks. In these cases it might take 5 minutes to load up the machine and get it started, plus another minute at the end to unload it. In between, the machine can chug away unattended working about as fast as the human allowing the human to do other work while the robot is running. This reduces the chance of repetitive stress injuries and can improve the precision of the assay. At sufficient scale, for example, that seen at diagnostics testing companies, automation of these tasks is critical, but if you’re not performing the operation hundreds of times per day, it’s probably not worth automating yet.
A task that used to take 20 minutes now takes 26 minutes assuming you’re ready and waiting for the robot to finish. If you carefully orchestrate your time in the lab each day, it may be possible to be more productive with all of these helpful tasks automated. In practice, this rarely happens. Even when it does, the total length of time required to accomplish the same set of tasks will often lengthen. Had we chosen to ignore these applications of automation from the beginning we would have freed up more time to optimize the crucial and tedious solutions more rapidly. A set of programmable handheld pipettes can handle most workflows and have the benefit of visual observation to check for issues with volume as the pipetting is happening.
Monitoring the performance:
Implementing automation allowed us to scale the number of weekly experiments and reduce costs which led to an explosion of data. Much of that data was from experiments testing and optimizing our new automated workflows. Because we invested early in defining our quality metrics and automating their calculation, we could easily review this increasingly large dataset and track results back to their experimental conditions. This allowed us to rapidly identify process improvements, increasing the success rate of the assay.
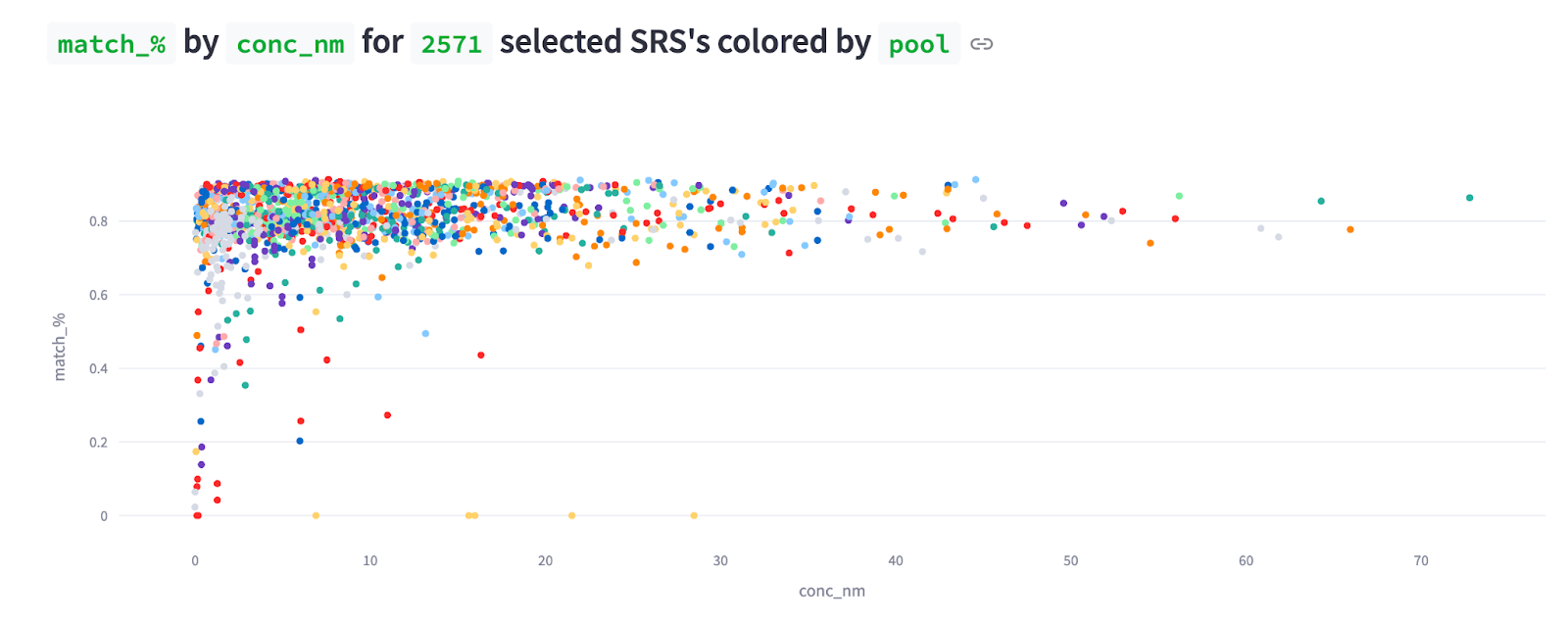
Earlier in this series I shared this same screenshot with only 507 selections. Now we’re at 5X that and the general trend we’ve observed is holding.
A significant advantage in our crucial automation tasks was our ability to observe their output immediately. Our protein purification workflow begins with visual confirmation and ends with quantification and gel-analysis. Variables introduced by the automated process can be quickly identified and pinpointed. Similarly, the PCR set-up process is followed by quantification and gel analysis as well. This again allows us to rapidly identify issues with automation. Because we had invested in automating the data collection from these systems, it was easier to track performance back to specific root causes allowing for a variety of improvements.
Other Considerations:
Automation control software for these lab automation systems is almost uniformly weird and not very good. Most of the time you’re stuck with whatever comes with the best (or most affordable) hardware. For us, that meant using Venus to control our Star, i-Control for the Tecan M200, something else for the 2D scanner, something else for the KingFishers, the thermocyclers are programmed via a touch-screen on the device. It’s all different, and it’s almost always not very good at doing exactly what you want without a lot of effort. The worst part is that the method files are often binary or encrypted and incompatible with version control systems used for all other code bases. This can make implementing and tracking changes difficult.

Building some flexibility into new automation methods is helpful. Exposing critical volumetric parameters as variables makes the methods easier to use.
To minimize this problem we put the minimum amount of logic into this vendor provided software and their opaque files. It is possible to parse and sort a csv file from the 2D scanner and build a worklist directly with Venus commands, but much better to just run a custom executable that Venus can call and collect the output from. This critical logic can then be written in standard languages and properly version controlled. Don’t perform logic or calculations inside vendor provided software when scripts or executables are available. For each software package, figure out how to export and store the most critical information in whatever format the software provides. Tecan's i-Control XML files are particularly nice. They’re a complete record of all parameters used, the serial number of the instrument, the time, and the data. We store each one to a Google Cloud Bucket via our Quant app each time we use it to calculate concentrations.
Takt time and capacity planning are critical concepts to consider as you scale, and especially as you link more automated workflows together. You can only move as fast as your slowest step. If each step operates with a different cadence, you can have a huge range of time between operations—introducing unexpected and often untracked variation. At our current scale, we do calculate how many purifications, selections, and PCRs we can run per day at how many samples per run of each to make sure we’re pacing appropriately throughout the week and making sure we have enough time on the instrumentation to make the work flow smoothly. As scale increases this becomes more and more critical.
Volume ranges and acceptable tolerances need to be defined. No liquid handling system can deliver 10ul every time. Many will promise an average of 10ul with a CV of less than 5%. What matters more is, how many times in a million will it deliver a volume less than 8ul or more than 12ul? Understanding what your process requirements are and measuring them according to those limits is often more useful than CV. In general, volumes from 2ul to 1ml are pretty great for current lab automation. Below 2ul changes in viscosity, surface tension, temperature can start to have a big effect. Above 1mL it starts to take too long. Make sure you understand how tolerant your process is to variation and measure how variable your process is likely to be. You can use this to ensure your process is capable of the work you’re asking it to perform.
These were some of the most critical and useful considerations for us at Leash. There are obviously hundreds of other factors that go into successful implementation of lab automation, but I’ll leave it here for now. I’d love to hear questions and feedback for future topics, this is the end of the series for now. I’m sure there are more topics that we could cover. If people have specific interests please let me know! I’d love to hear from you!